Learning Background-Aware Correlation Filters for Visual Tracking
ICCV 2017
Correlation Filters (CFs) have recently demonstrated excellent performance in terms of rapidly tracking objects under challenging photometric and geometric variations. The strength of the approach comes from its ability to efficiently learn - on the fly - how the object is changing over time. A fundamental drawback to CFs, however, is that the background of the target is not modeled over time which can result in suboptimal performance. Recent tracking algorithms have suggested to resolve this drawback by either learning CFs from more discriminative deep features (e.g. DeepSRDCF and CCOT ) or learning complex deep trackers (e.g. MDNet and FCNT). While such methods have been shown to work well, they suffer from high complexity: extracting deep features or applying deep tracking frameworks is very computationally expensive. This limits the real-time performance of such methods, even on high-end GPUs. This work proposes a Background-Aware CF based on hand-crafted features (HOG) that can efficiently model how both the foreground and background of the object varies over time. Our approach, like conventional CFs, is extremely computationally efficient- and extensive experiments over multiple tracking benchmarks demonstrate the superior accuracy and real-time performance of our method compared to the state-of-the-art trackers.
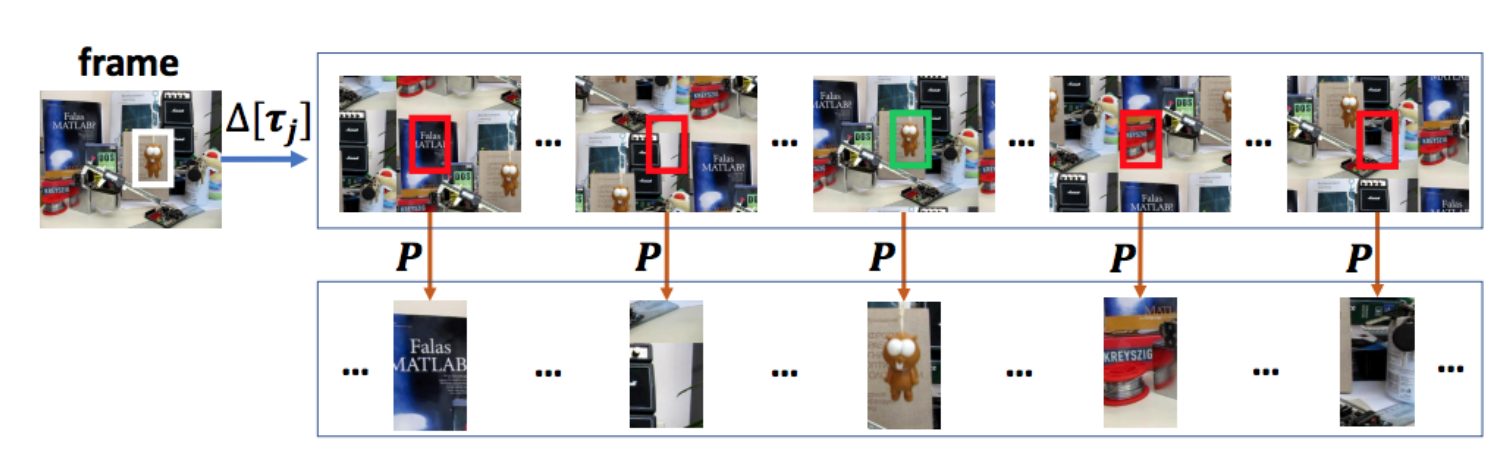
Figure 1: BACF learns from all possible positive and negative patches extracted from the entire frame. The shifting operator generates all circular shifts of the frame over all j = [0, ..., T-1] steps. T is the length of vectorized frame. P is the cropping operator (a binary matrix) which crops the central patch of each shifted image. The size of the cropped patches is same as the size of the target/filter (D), where T >> D. All cropped patches are utilized to train a CF tracker. In practice, we do not apply circular shift and cropping operators. Instead, we perform these operations efficiently by augmenting our objective in the Fourier domain. The red and green boxes indicate the negative (background) and positive (target) training patches.
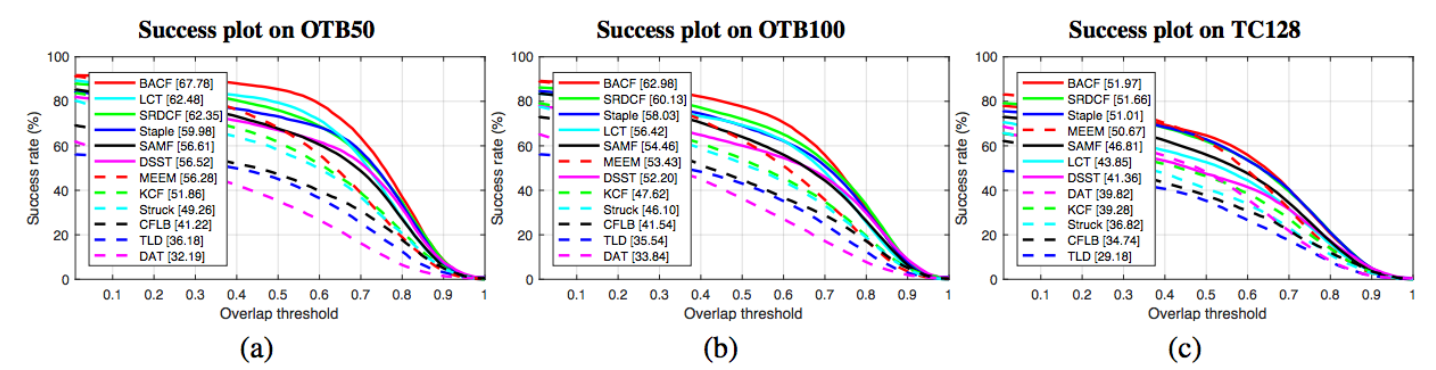
Figure 2: Success plots comparing BACF with the state-of-the-art HOG based trackers on (a) OTB50, (b) OTB100, and (c) TC128. The result of top 12 trackers is illustrated here. AUCs are reported in brackets.

Table 1: Success rates (% at IoU > 0.50) of BACF versus HOG-based trackers.
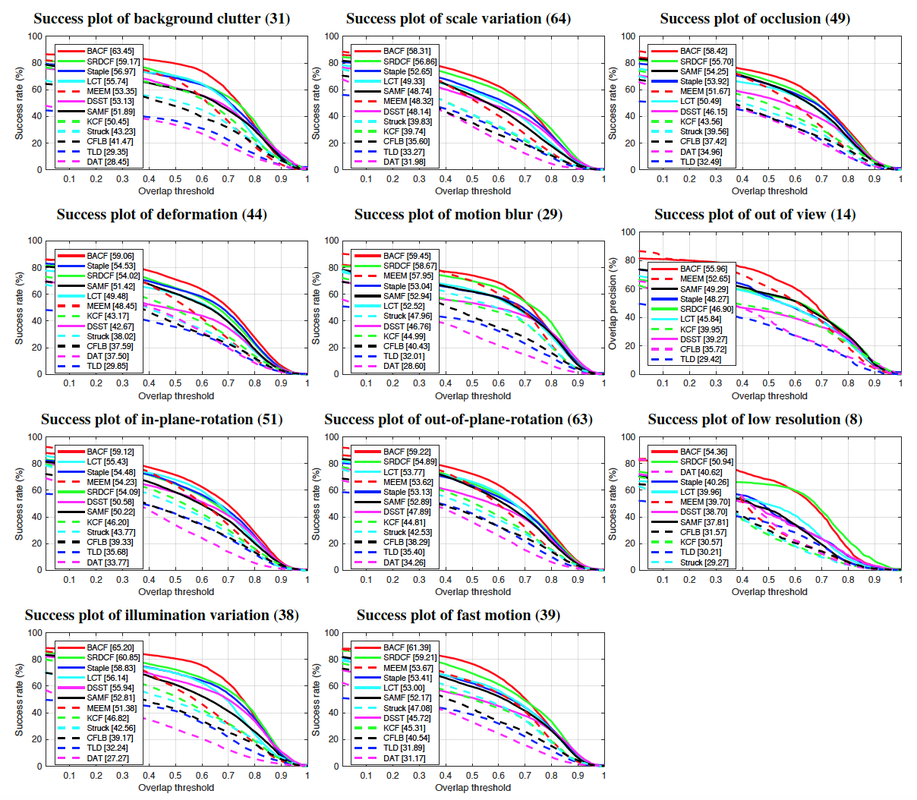
Figure 3: Attribute based evaluation. Success plots compare BACF with state-of-the-art HOG based trackers on OTB100. BACF outperformed all the trackers over all attributes. AUCs are reported in brackets. The number of videos for each attribute is shown in parenthesis.
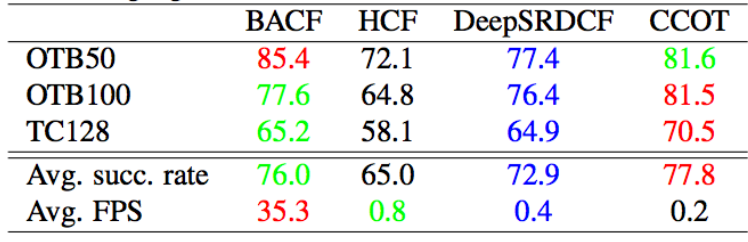
Table 2: Success rates (% at IoU > 0.50) of BACF compared to CF trackers with deep features.
|
IF you are using the uploaded code and you getting slightly different results, you should check the OTB-50(100) annotation. For some videos, the annotation files should be fixed for start/end frames. This is considered in our implementation/code by:
David : st_frame = 300; en_frame = 770;
Football1: st_frame = 1; en_frame = 74;
Freeman3: st_frame = 1; en_frame = 460;
Freeman4: st_frame = 1; en_frame = 283;
It is suggested to use the uploaded MAT files for OTB-50(100) and the evaluation code to reproduce the results reported in our paper.
for any question/comment please email me: [email protected] (My CMU email does not work anymore).
David : st_frame = 300; en_frame = 770;
Football1: st_frame = 1; en_frame = 74;
Freeman3: st_frame = 1; en_frame = 460;
Freeman4: st_frame = 1; en_frame = 283;
It is suggested to use the uploaded MAT files for OTB-50(100) and the evaluation code to reproduce the results reported in our paper.
for any question/comment please email me: [email protected] (My CMU email does not work anymore).
Tracking samples on OTB-100 dataset
Turbo bacf
Turbo BACF- a super fast version of the original BACF. It tracks more than 300 FPS on higher frame rate videos (240 fps).
The core technique is BACF (above code), however, the code is carefully tailored for tracking aerial videos:
0) the code is optimized.
1) we use a different strategy to handle scaling
2) a single module (either scale update, scale prediction, or tracker update) runs per each frame
3) tracking- position prediction- runs every single frame
4) the videos are higher frame rate of 240 fps- some are captured by a drone, some are borrowed from YouTube.
(the code can't be released for now, but feel free to contact me for any question/comment).
The core technique is BACF (above code), however, the code is carefully tailored for tracking aerial videos:
0) the code is optimized.
1) we use a different strategy to handle scaling
2) a single module (either scale update, scale prediction, or tracker update) runs per each frame
3) tracking- position prediction- runs every single frame
4) the videos are higher frame rate of 240 fps- some are captured by a drone, some are borrowed from YouTube.
(the code can't be released for now, but feel free to contact me for any question/comment).